Moving by Looking: Towards Vision-Driven Avatar Motion Generation
Human-like motion requires human-like perception. We create a human motion generation system is purely driven by Vision.

Human-like motion requires human-like perception. We create a human motion generation system is purely driven by Vision.
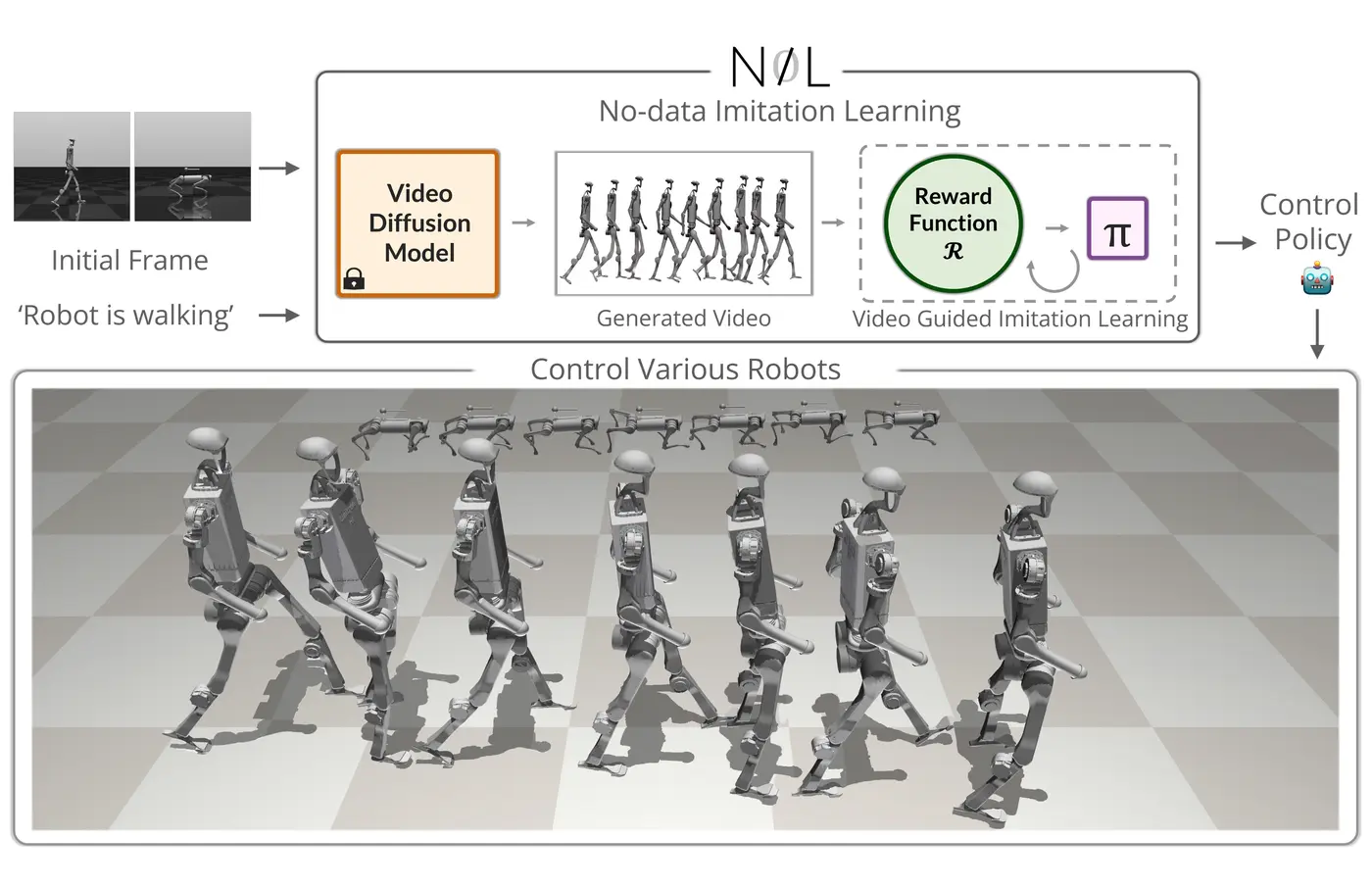
NIL introduces a data-independent approach for motor skill acquisition that learns 3D motor skills from 2D-generated videos, with generalization capability to unconventional and non-human forms. We guide the imitation learning process by leveraging vision transformers for video-based comparisons and demonstrate that NIL outperforms baselines trained on 3D motion-capture data in humanoid robot locomotion tasks.
WANDR is a conditional Variational AutoEncoder (c-VAE) that generates realistic motion of human avatars that navigate towards an arbitrary goal location and reach for it. Input to our method is the initial pose of the avatar, the goal location, and the desired motion duration. Output is a sequence of poses that guide the avatar from the initial pose to the goal location and place the wrist on it.

The MotionFix dataset is the first benchmark for 3D human motion editing from text. It contains triplets of source and target motions, and edit texts that describe the desired modification. Our dataset allows both training and evaluation of models for text-based motion editing. TMED is a conditional diffusion model trained on MotionFix to perform motion editing using both the source motion and the edit text.
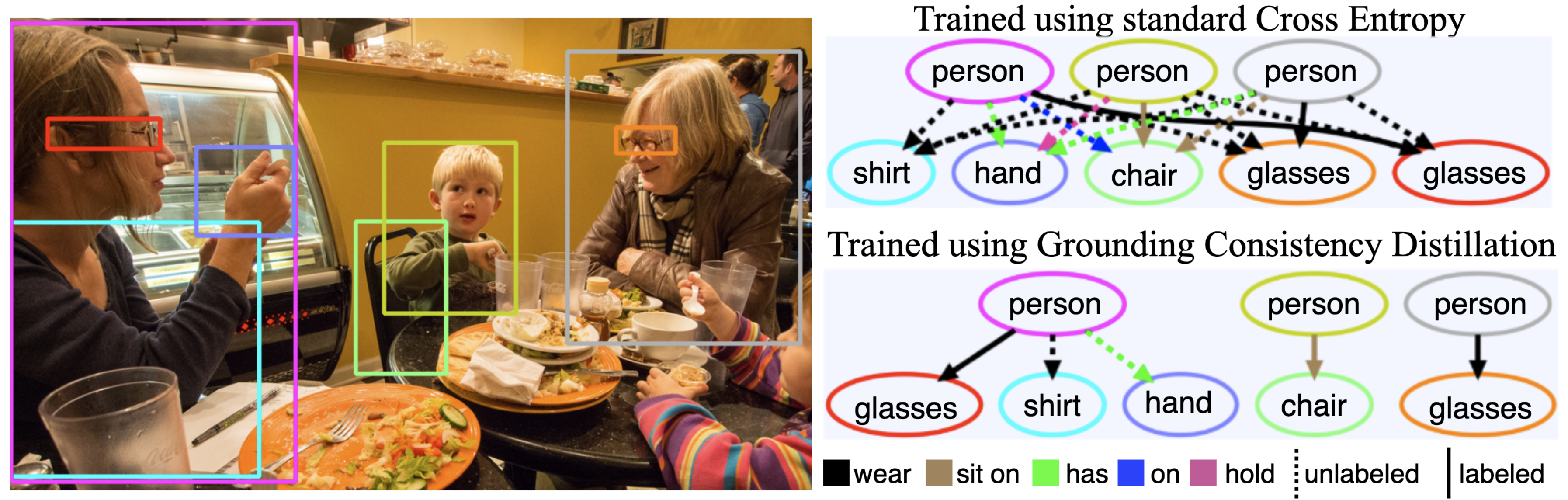
We propose a semi-supervised scheme that forces predicted triplets to be grounded consistently back to the image, addressing context bias in Scene Graph Generators through spatial common sense distillation.